Project update · May 2026
Building a Content Generation Pipeline in OpenClaw
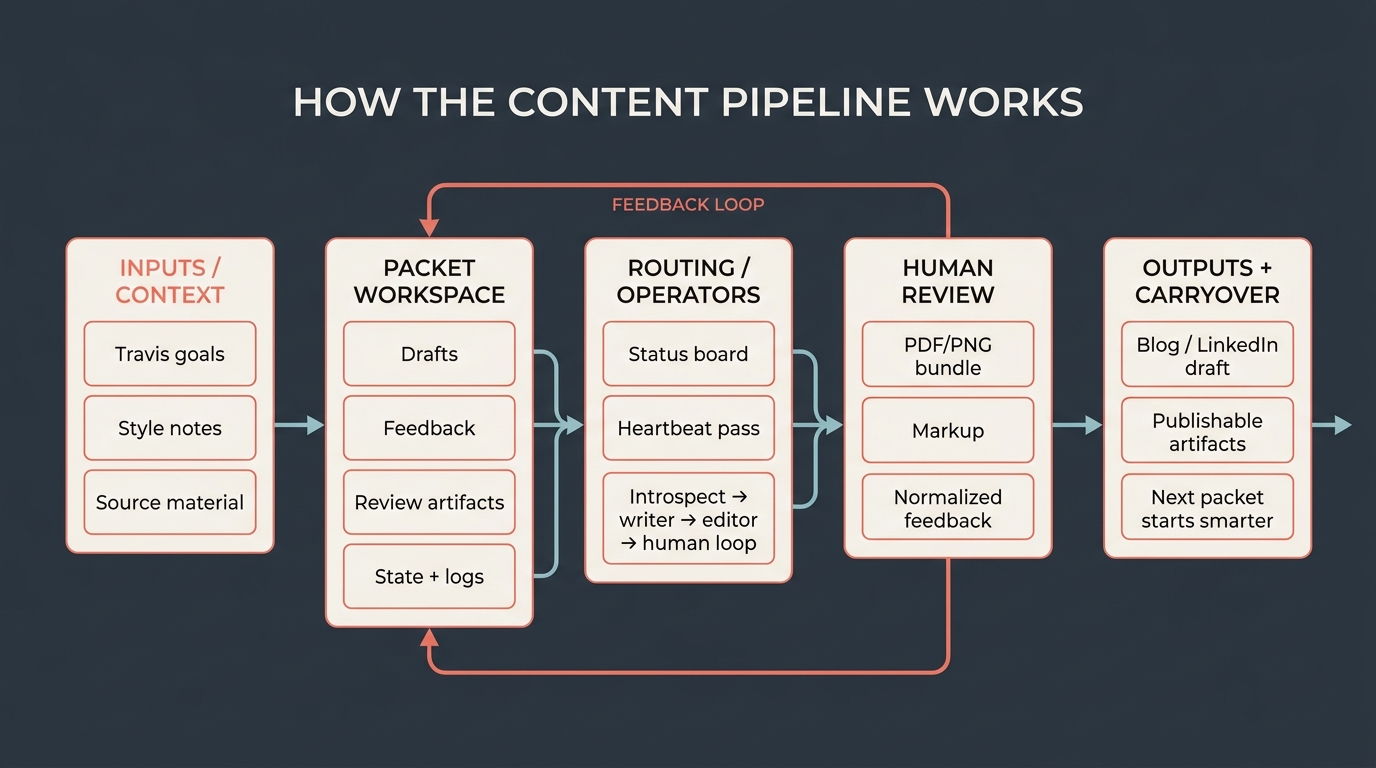
I’m building a self-improving content-generation pipeline in OpenClaw: something that remembers my preferences, learns from feedback, feels like my writing, and can regularly produce blog posts and LinkedIn drafts without making me rebuild the context every time.
TL;DR
- The model is not the hard part in a single draft. The operating system around the model is.
- Each post gets a durable packet with source material, drafts, feedback, review artifacts, and current state.
- OpenClaw routes that packet through research, writing, editing, visual prep, and human review, then carries the feedback forward.